Predicting Distribution Transformer Failures

Commonwealth Edison delivers power to 4 million customers in northern Illinois, U.S., including the entire city of Chicago. More than 90% of these customers have advanced metering infrastructure (AMI) meters that report voltage and load readings in 30-minute intervals. This unprecedented volume of data not only enables a deeper understanding of the operation of the system, it provides the utility a means to perform predictive analytics — the exploration of data with machine learning methods — to predict distribution transformer outages. The machine learning methods applied also may be used for predictive analytics on any devices where downstream data is being collected.
About 2000 distribution transformers fail each year on ComEd’s system (less than 0.5% of the entire transformer population). As widely known in the industry, the point of failure for some transformers is preceded by an abnormally high output voltage from a fusion of the high-side windings, which changes the effective ratio of the transformer. Subject matter experts at ComEd asserted a similar failure mode exists wherein the low-side windings fuse, resulting in an abnormally low output voltage. The voltage profile of one of ComEd’s transformers exhibited this behavior before failure.
Examining the data further revealed a third failure mode, wherein the iron core of a transformer becomes saturated under heavy load, resulting in low output voltages during peak load hours. In addition to these known causes, many failures are attributable to weather, wildlife and other unpredictable variables. This analysis, however, did not attempt to predict these failures.

Data Preprocessing
ComEd’s raw data had several problems that needed to be resolved before the utility could develop any outage prediction models. First, because many transformers have multiple meters downstream, a representative voltage profile needed to be determined for each transformer. Using a data sample of 90 days, the absolute value of the voltage difference between all pairwise combinations of downstream meter readings was calculated for each point in time on each of the 500,000 distribution transformers at ComEd. From these calculations, it became evident it is common for two meters under the same transformer to have readings of more than 10 V apart at the same time.

Because a voltage dip or spike of even 5 V can indicate potential failure, it was necessary to select meters carefully and aggregate the voltage readings of only the meters that best characterize each transformer. To do this, a mathematical method of automatically ignoring outlying data and identifying the most representative voltage measurements was developed. Because of the volume of data involved in these operations, it was necessary for the algorithm to be implemented in an extremely efficient manner. It should be noted a similar selection and aggregation process must be implemented for any study that uses AMI readings to analyze upstream devices.
After this first stage of preprocessing, each transformer was left with a series of 4320 voltages corresponding to 48 readings per day for the 90-day period. However, after comparing these aggregated voltages across transformers on different feeders and phases, it became clear no voltage threshold could be used on data across the grid to determine a significant number of transformers at risk of failure.
An extreme voltage reading followed by failure for one transformer could appear to be a normal operational reading for another due to varying voltages in feeders across the system. The solution was to calculate a locally normalized signal for each transformer based on the voltage signals of its neighbors on the same feeder and phase. After calculating this second signal for each transformer, visual analytics showed it could represent the three failure scenarios.
For each transformer, a final binary data point was added to indicate whether a transformer failed within six weeks of the sample data. This was used as the response variable during model training.


Model Training and Results
Supervised machine learning involves extracting features from data sets, designing and tuning a model, and training and testing the model on sample data to evaluate its efficacy. For binary classification models, a receiver operating characteristic (ROC) curve is a plot of the true positive rate (TPR) against the false positive rate (FPR) of the model predictions at various discrimination thresholds. Typically, the area under the ROC curve (AUC) is used to measure the performance of a model, where an AUC of 1 represents perfect predictive power. It should be noted for accurate model evaluation, the data used to train the model is separate from that used to test it. For this study, the sample data was split randomly into two sets: 80% for training and 20% for testing.
Because little existing research uses machine learning methods with data from AMI meters, ComEd took three approaches to predict failures. For all three methods, the goal was to predict whether a transformer would fail within six weeks of the data set.
The first approach used a feed-forward deep neural network (DNN) on the raw data. DNNs can estimate complicated nonlinear, continuous functions through stochastic gradient descent. One data point is fed into a DNN model at a time, and the internal parameters of the model are updated based on the current model prediction error.
Data was formatted into a columnar format in which there were five columns: transformer identification, time stamp, two signal values and whether the transformer had failed. This method yielded a model with a moderate AUC of 0.7 on the test data set. Performance was hindered by the high cardinality of the categorical column indicating transformer ID. Depending on the method used to encode all values of this column into model inputs, the model either differentiated between transformers poorly or slowed training by introducing an additional input variable for each of the transformers.
For the second approach, features were extracted from the data using digital signal processing techniques. The intensities of the power spectrums of both signals corresponding to each transformer were calculated at several handpicked frequencies. In addition, the gradients with respect to time and the L1 and L2 norms of the signals were calculated. Using these features as model inputs, a DNN model with a more acceptable AUC of 0.75 on the test set was trained.
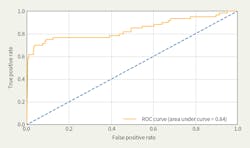
In the third approach, a gradient-boosting machine was used. Unlike DNNs, gradient-boosting machines do not predict a continuous function. Instead, the trained model is more like a very large flow chart used to predict a response based on the values of the model inputs. Because of these tree-based decisions, gradient-boosting machines typically perform well on classification problems. The raw data was formatted into 8641 columns where each row represented a single transformer; 8640 columns represented specific moments in time for the two signals and one column represented whether the transformer failed. The model yielded an AUC of 0.84 on the test set with a very low FPR at high discrimination thresholds.
For the purposes of this study, the FPR was important because of the extremely skewed nature of the data. As an example, an FPR of 1% at a 50% TPR would — on a hypothetical system where 0.1% of the transformers fail within the next six weeks — predict failure for 20 times as many nonfailing transformers as failing transformers, which would not be acceptable results from a business perspective.
Note that a TPR of just under 60% can be achieved while introducing almost no false positives. This last method of model training also is robust; similar ROC curves were obtained even when truncating or removing random input columns from the data. This proves there is a signature for the failing transformers in the voltage data that can be learned by supervised machine learning models.
Future Studies and Applications
The most effective approach was used on three different 90-day periods (spring 2015, summer 2016 and summer 2017), and it performed well on each. However, training a model on one period and predicting on another yielded poor results. This is because each column of data used in this method represented a fixed point in time for every transformer when all were experiencing similar loading conditions (for example, one column represents 2 p.m. on a hot summer Saturday and another represents 1 a.m. on a cool weeknight). By formatting the data so time was consistent, the missing load information — which is the true driver for current and, therefore, failures — was artificially substituted into the model.
Because the main goal of this study was to predict transformer outages before they happen, the model must be able to predict outages using data outside the period of its training data. In the future, load will be added to the data and models will be developed that are abstracted from time.
This study shows it is possible and within business reason to perform predictive analytics on the scale of individual devices using data collected downstream from those devices. As utilities continue to install infrastructure that enables the processing of higher volumes of data, it will be possible to perform more accurate analyses on various types of devices. ♦
Max Kimmet graduated with a BSME degree from the University of Illinois at Urbana-Champaign in 2016. Since then, he has been working as an associate engineer at Commonwealth Edison Co. with a focus on big data analytics. He is currently working on predicting distribution transformer outages and projecting distribution-pole reject rates.
Norayr Matevosyan obtained his Ph.D. in mathematics in 2003 from Royal Institute of Technology, Stockholm, Sweden. He worked as a research scientist and lectured at RICAM–Linz, Austria; University of Vienna, Austria; University of Cambridge, UK; and University of Texas at Austin. Since 2015, he has been working as a principal data scientist at Commonwealth Edison Co. His current research interests include developing outage prediction models for grid assets.
About the Author
Max Kimmet
Max Kimmet graduated with a BSME degree from the University of Illinois at Urbana-Champaign in 2016. Since then, he has been working as an associate engineer at Commonwealth Edison Co. with a focus on big data analytics. He is currently working on predicting distribution transformer outages and projecting distribution-pole reject rates.
Norayr Matevosyan
Norayr Matevosyan obtained his Ph.D. in mathematics in 2003 from Royal Institute of Technology, Stockholm, Sweden. He worked as a research scientist and lectured at RICAM–Linz, Austria; University of Vienna, Austria; University of Cambridge, UK; and University of Texas at Austin. Since 2015, he has been working as a principal data scientist at Commonwealth Edison Co. His current research interests include developing outage prediction models for grid assets.